The Hope and Prayer of a Contractor
My family and I love to play pickup basketball games together in our backyard. We do however, live in Texas, and as you probably know, Texas summers are hot. Due to the heat, we decided it would be wise to install an overhead light on the basketball court so we could play hoops when the sun goes down. Since I’m not electrician, we contracted out the work in early February.
Well, it’s now the middle of August and we’re still waiting for the electrician to finish his job. Last week I was pressing the general contractor for a commitment for a specific day for the work to be done. Let’s just say his response was not exactly what I was expecting.
“He said next week for sure. Praying that happens.”
Now, I am a very religious individual and strongly believe in the power of prayer. I even believe prayer should be invoked on behalf of our businesses and livelihood.
However, I believe prayer is a tool to be used after we’ve done everything possible on our end to bring about our desired outcomes. I do not believe prayer should be a tool used as a crutch to overcome our own lack of effort and planning (James 2:20). A general contractor, in my opinion, should be able to effectively work with his team and his subcontractors to gain commitments and delivery dates without doing anything more than throwing it onto the wings of hope and prayer.
How Does this Relate?
So what does this story have anything to do with patching processes for Macs?
To that, I say, good question. In response, I’ll answer your question with a question. Are you secretly relying solely on hope and prayer that the Macs in your environment will simply be self-managed by the savvy users that employ them? After all, Mac users want to be treated differently, right?
I was on a phone call again on Friday and asked the IT administrator if they have just Windows devices employed in their environment, or if they have anything else such OS X devices and/or Linux devices that he would need to manage. His response is about as common as it gets.
“We have some Macs, the total number of which is growing, but it’s mainly just our marketing team and several of our executives. At this time, we don’t manage them.”
You don’t manage them? Wow! How often do we hear the idiom “a chain is only as strong as its weakest link?” Why do organizations invest so much time and money in their infrastructure when they’re only going to patch a percentage of the total attack vectors, leaving the remaining portion to chance…or was that to hope and prayer?
The Vulnerability Data
Common Vulnerabilities and Exposures is reporting that OS X has 178 new security vulnerabilities published in 2015 alone. To compare, that’s more than 2013 and 2014 combined and we still have a third of the year to go – this data only includes vulnerabilities released up until the first week of July. It doesn’t account for the latest zero-day vulnerabilities being reported this week here and here. Furthermore, of the 178 vulnerabilities, 25 of them allow the attacker to gain additional privileges on the compromised system. To put that into perspective, 25 new privilege vulnerabilities is greater than all previously reported exploits of the same type over the last eight years combined!

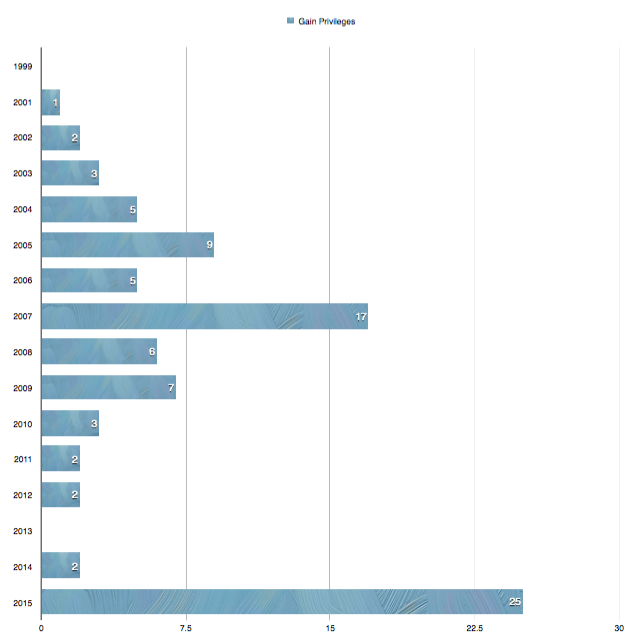
Hoping and praying an attack doesn’t surface, through the management process of “look the other way”, is incredibly risky and could potentially cost you millions. Infosec Institute is reporting that in 2013 “the average annualized cost of cybercrime incurred per organization was $11.56 million, with a range of $1.3 million to $58 million.”
So What Do I Do?
Sounds like it’s time to quit relying on just hope and prayer and to put forth some action. So where do you start? First and foremost, obtain a tool that allows you to scan your managed machines against a known vulnerability list that you can control, and ensure your machines scan on a frequent basis and then centrally report up their results.
Just knowing where you stand against the 178 new vulnerabilities is a great start. It will also give you the information you need to make intelligent business decisions.
Notice that I mentioned you will now have the data to make intelligent business decisions. Blindly patching all 178 vulnerabilities without properly testing them, while better than completely ignoring them altogether, is not moving forward intelligently. If you were to blindly patch everything, there’s a good chance you could break a critical business process which in turn could potentially affect your organization to the tune of millions of dollars as well. So be careful and use caution.
Many security pundits will encourage you to test and evaluate new patches in phases. Apple doesn’t have a “Patch Tuesday” so you’ll need to be constantly vigilant about when Apple releases new security updates. Hopefully the tool you use to scan your machines can notify you of new content. If not, keep on an eye on Apple’s Security Updates page found here.
I personally like to break down my patch process into five distinct phases:
- The lab test phase
- The smaller, more controlled initial test pilot phase
- The larger, greater reach secondary pilot phase
- The mass rollout phase
- The exception handling phase
The size of your organization and the resources available may force you to adapt, and that’s alright. It’s the checks and balances part that is critical.
The Lab Test Phase
Inside the lab test phase, you should have replica environments for the different types of configurations you have deployed in your environment. Keep them up to date with reality. Make sure when you update your critical business applications in production that you also update your test lab machines. Almost as important, make sure you downgrade the business critical applications to the current release version when testing new security content. Don’t think just because the Apple security update works with version 2.2.x of your business app that it will also work with version 2.1.x.
In order to advance out of the lab test phase, ensure that your exit criteria has been defined and that it meets your success metrics. These metrics may be as simple as defining a machine has been patched, it still can be logged into and that the critical business applications can still be opened. You may also decide to get much more granular, that’s up to you and your organization’s tolerance for risk. What’s important is that a set of defined exit criteria has been established. You can’t be successful if you don’t know what success looks like. Once you have success, document the status of your exit criteria with times and dates and move on.
In regards to timing, when new content comes out, you should be immediately testing against your lab machines.
The Smaller, More Controlled Initial Test Pilot Phase
Once you’ve validated the content against your lab machines and have met your successful exit criteria, move on to a focused pilot group. This is stating the obvious but members of this pilot group need to be using machines that match the type of devices deployed to your entire corporation. That may mean you’re going to need to find dozens of different types of users to match finance, engineering, marketing, etc. Understanding your different user types is critical. Furthermore, these individuals need to be flexible and must be willing to communicate when things don’t work. Build feedback channels into your process that are easy to use. If something breaks, the pilot test group user should know exactly how to contact you with the information you desire.
The next obvious step is to notify the pilot group that patches are coming so they know to be alert and aware.
Just like with the lab test phase, define your exit criteria and document it. Not everyone in your pilot group is going to be available 100 percent of the time. You may have to settle with a 100 percent approval rating from your test group, or up to seven business days. Define what success is, establish the process, and once you can quantify whether you’ve hit your metrics, move on. If you can’t meet your success metrics due to issues, single out the offender and proceed with the rest while you move the offender into the exception handling process.
Ideally, you should be able to wrap up this phase within three to 10 business days from the initial content publication date.
The Larger, Greater Reach Secondary Pilot Phase
The larger pilot phase is nearly identical to the first, only this time increasing the amount of participants. Maybe you move from 2 percent of your machines to five to 10 percent of your machines. Due to the greater number of participants, you may need to be more lax in your exit criteria. You may decide that if 75 percent of your participants approve, or if seven business days have transpired, you have sufficient information to move on. When things break, people complain. When it comes to patch, no news is often good news, that’s why we can put time down as a successful metric. It’s not perfect, there are always those applications that are run on a periodic basis, but it’s a start. Just document were you stand and move on.
Again, just make sure the proper notification is going out to your pilot group so they know to be aware and provide them with dates they need to respond by. Ensure the proper channels are in place so the pilot users can communicate the good and the bad.
This phase should put you two to three weeks out from the content’s publication date. Remember, time is not on your side. The key is to be disciplined, yet focused on getting the content released.
The Mass Rollout Phase
Here comes the fun part, let’s roll out the patch updates to the rest of the organization. While no process will prevent every potential bad outcome, enter into the mass rollout phase with confidence. It won’t hurt to hope and pray at this point either, but at least you’ve done your part.
The key to this portion is to capture the feedback and learn. If a certain individual or group is adversely affected, understand how he/she/them differ from your pilot test groups. Consider adding in this individual or a member from the group into your pilot phase for future testing. The outspoken, high-energy individuals are usually willing to participate in such programs, so bring them in.
Make sure you’re using your patch tool to track the progress. You should be able to hit a pretty high success criteria within days of release.
Where I see most companies struggle here is with off-network devices. Ideally your patch tool should be able to handle the delivery of a patch regardless of where it sits, whether on or off the network. If it doesn’t, you may want to re-evaluate your tool. Machines are always going to be offline or off network, sometimes for days, weeks, months or even indefinitely. Build your process around the exceptions and you’ll be successful.
The Exception Handling Phase
Use this phase to deal with all of the one-off scenarios. It may be a single system that causes you grief. It may be a patch that will not apply. It may be hardware that fails months after patches have been applied, making you vulnerable to items you thought you had patched months ago.
Every scenario is going to be unique and require a different set of steps to troubleshoot. Figure out what you can and then re-insert it back into your patch workflow when it’s ready to be re-evaluated. For me, what’s important, is to document, learn and use what you can to enhance your established patch process so that with each iteration it gets better and better.
Conclusion
Using your patch tool, you should be able track the trends and understand how quickly you can turn around a patch. What may take 35 days can be gradually improved to 30 days, then into the 20s, the 10s and maybe even into single digits. The size of an organization will have such an impact on turn around that comparing against others is not as important as comparing against yourself.
Now, after implemented your newly minted and customized patch process, continue to hope and pray what you’ve done is enough. Zero-day threats will always be with us, having 100 percent prevention is nigh impossible. But having done all that you can do and covering what is in your control, you can now use that prayer and hope to overcome what is outside your control.




















Recent Comments